Data Projects > Data Mining and Exploration
Text Mining with Python and the Natural Language Toolkit
For this project, I used Python and the Natural Language Toolkit (NLTK) to text mine 129,000 documents containing abstracts of National Science Foundation (NSF) awards for basic research.

Graduate course: CS 548 - Knowledge Discovery and Data Mining
Date: April, 2015,
Tools:
Data:
National Science Foundation (NSF) Research Award Abstracts 1990-2003 Data Set (http://archive.ics.uci.edu/ml/datasets/NSF+Research+Award+Abstracts+1990-2003)
Date: April, 2015,
Tools:
- Python
- Natural Language Toolkit (http://www.nltk.org/)
- Weka (http://www.cs.waikato.ac.nz/ml/weka/)
- Google Ngram Viewer tool (https://books.google.com/ngrams)
- Wordle - word cloud tool (http://www.wordle.net)
Data:
National Science Foundation (NSF) Research Award Abstracts 1990-2003 Data Set (http://archive.ics.uci.edu/ml/datasets/NSF+Research+Award+Abstracts+1990-2003)
Process
I organized the files into sub-folders. Each sub-folder had about 10,000 documents.
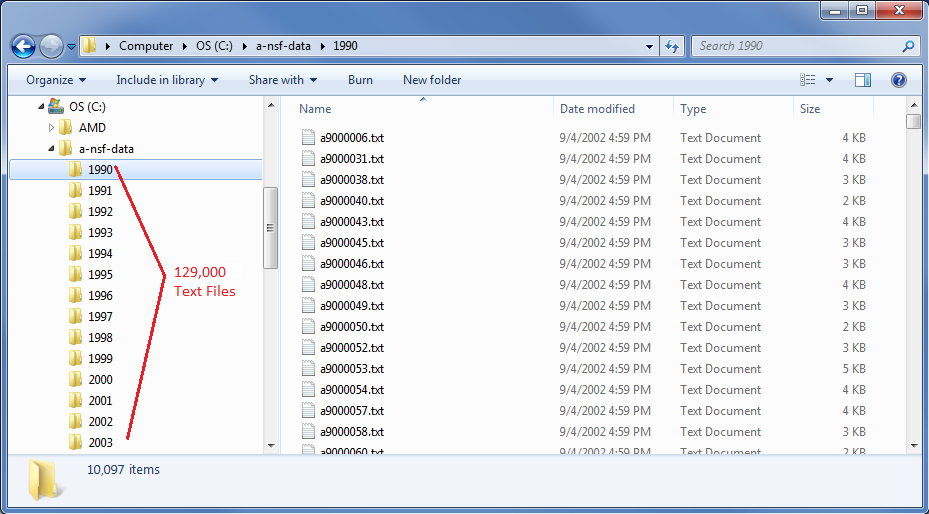
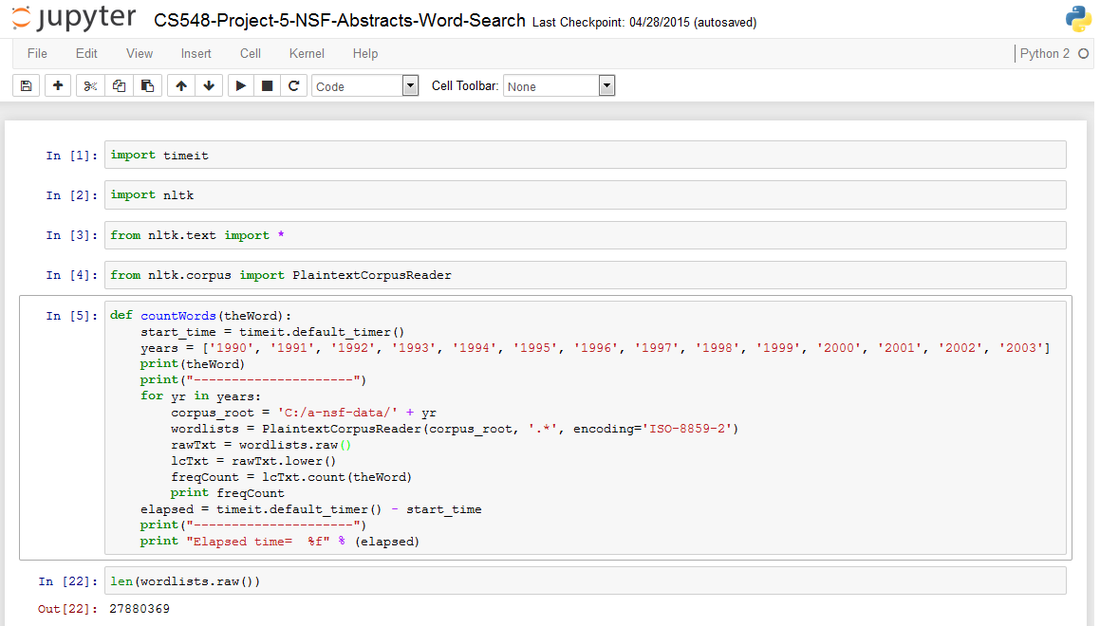
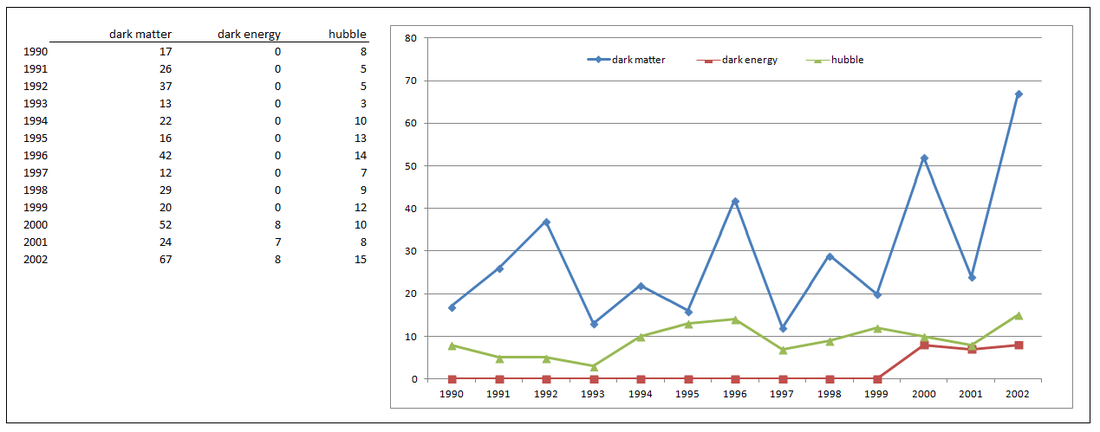
I used Python to iterate through each sub-folder, from 1990 - 2003, and count the occurrence specific research words.
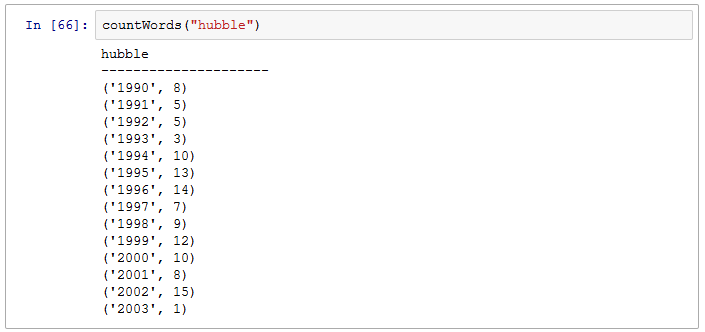
For example, I counted the occurrence of the word "hubble" for each of the years and output the results in a simple list.
Then I plotted those words across the years for comparison.
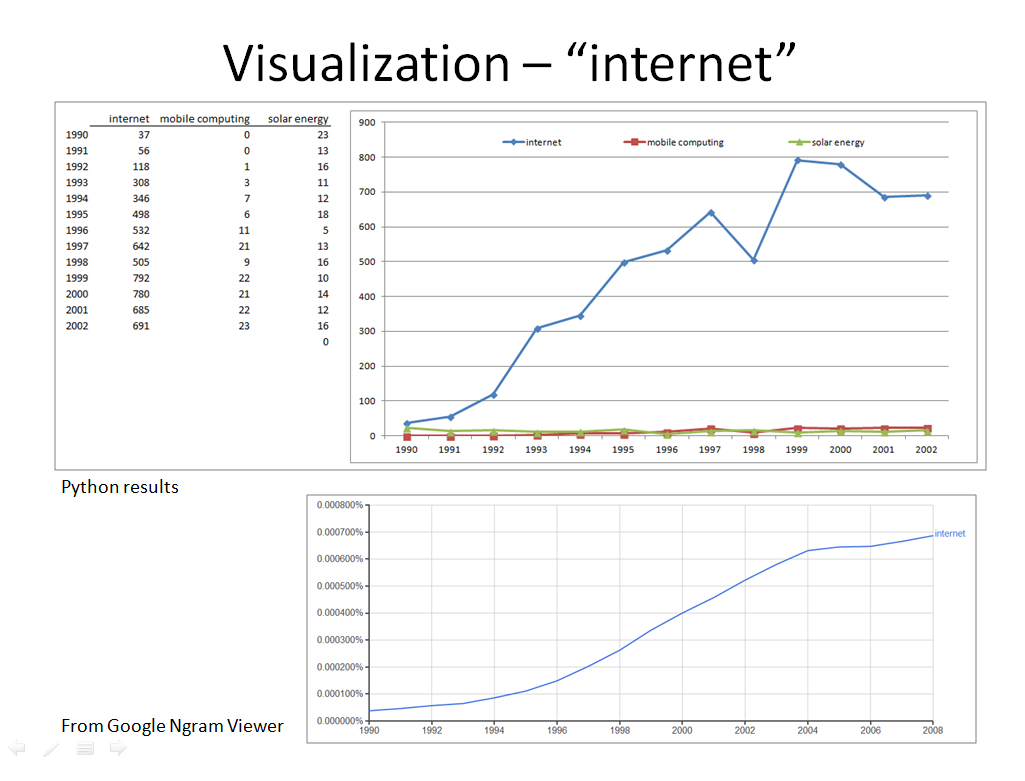
For some words, I also looked up them up in Google's Ngram Viewer to see how that word occurred in general during the same time. Here you can see the occurrence of "internet" in the NSF research documents compared with its occurrence as shown by Google Ngram Viewer.